knn_fit<-class::knn(train =x, test =x, cl =y, k =15)caret::confusionMatrix(table(knn_fit, y))
Confusion Matrix and Statistics
y
knn_fit 0 1
0 82 13
1 18 87
Accuracy : 0.845
95% CI : (0.7873, 0.8922)
No Information Rate : 0.5
P-Value [Acc > NIR] : <2e-16
Kappa : 0.69
Mcnemar's Test P-Value : 0.4725
Sensitivity : 0.8200
Specificity : 0.8700
Pos Pred Value : 0.8632
Neg Pred Value : 0.8286
Prevalence : 0.5000
Detection Rate : 0.4100
Detection Prevalence : 0.4750
Balanced Accuracy : 0.8450
'Positive' Class : 0
Code
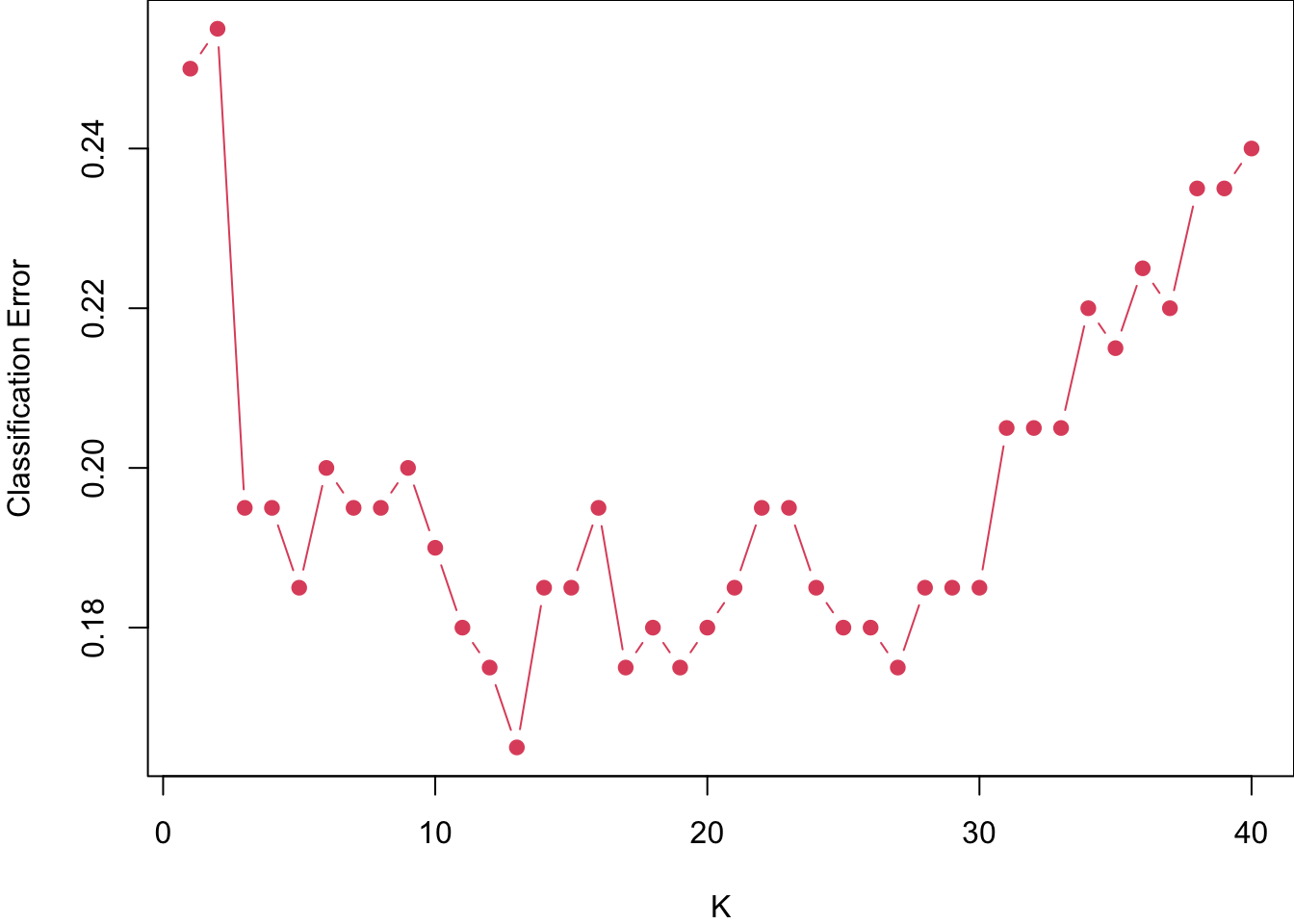
set.seed(2025)control<-trainControl(method ="cv", number =10)knn_cvfit<-train(y~., method ="knn", data =data.frame("x"=x, "y"=as.factor(y)), tuneGrid =data.frame(k =seq(1, 40, 1)), trControl =control)par(mar =c(4, 4, 0, 0))plot(knn_cvfit$results$k, 1-knn_cvfit$results$Accuracy, xlab ="K", ylab ="Classification Error", type ="b", pch =19, col =2)
Code
zip.train<-read.csv("../data/zip.train.csv")zip.test<-read.csv("../data/zip.test.csv")# fit 3nn model and calculate the errorknn.fit<-class::knn(zip.train[, 2:257], zip.test[, 2:257], zip.train[, 1], k =3)# overall prediction errormean(knn.fit!=zip.test[, 1])
[1] 0.05530643
Code
# the confusion matrixtable(knn.fit, zip.test[, 1], dnn =c("pred", "true"))
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import cross_val_scorefrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import confusion_matriximport rdata
Code
# Load the .rda file into a dictionarymixture_example = rdata.read_rda('../data/ESL.mixture.rda')
/Users/chenghanyu/.virtualenvs/r-reticulate/lib/python3.12/site-packages/rdata/conversion/_conversion.py:856: UserWarning: Missing constructor for R class "matrix". The underlying R object is returned instead.
warnings.warn(
Code
x = mixture_example['ESL.mixture']['x']y = mixture_example['ESL.mixture']['y']
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
KNeighborsClassifier(n_neighbors=15)
Code
pred = knn.predict(x)pd.DataFrame(confusion_matrix(y, pred), index=[f"Actual {int(i)}"for i in np.unique(y)], columns=[f"Pred {int(i)}"for i in np.unique(y)])
Pred 0 Pred 1
Actual 0 82 18
Actual 1 13 87
Code
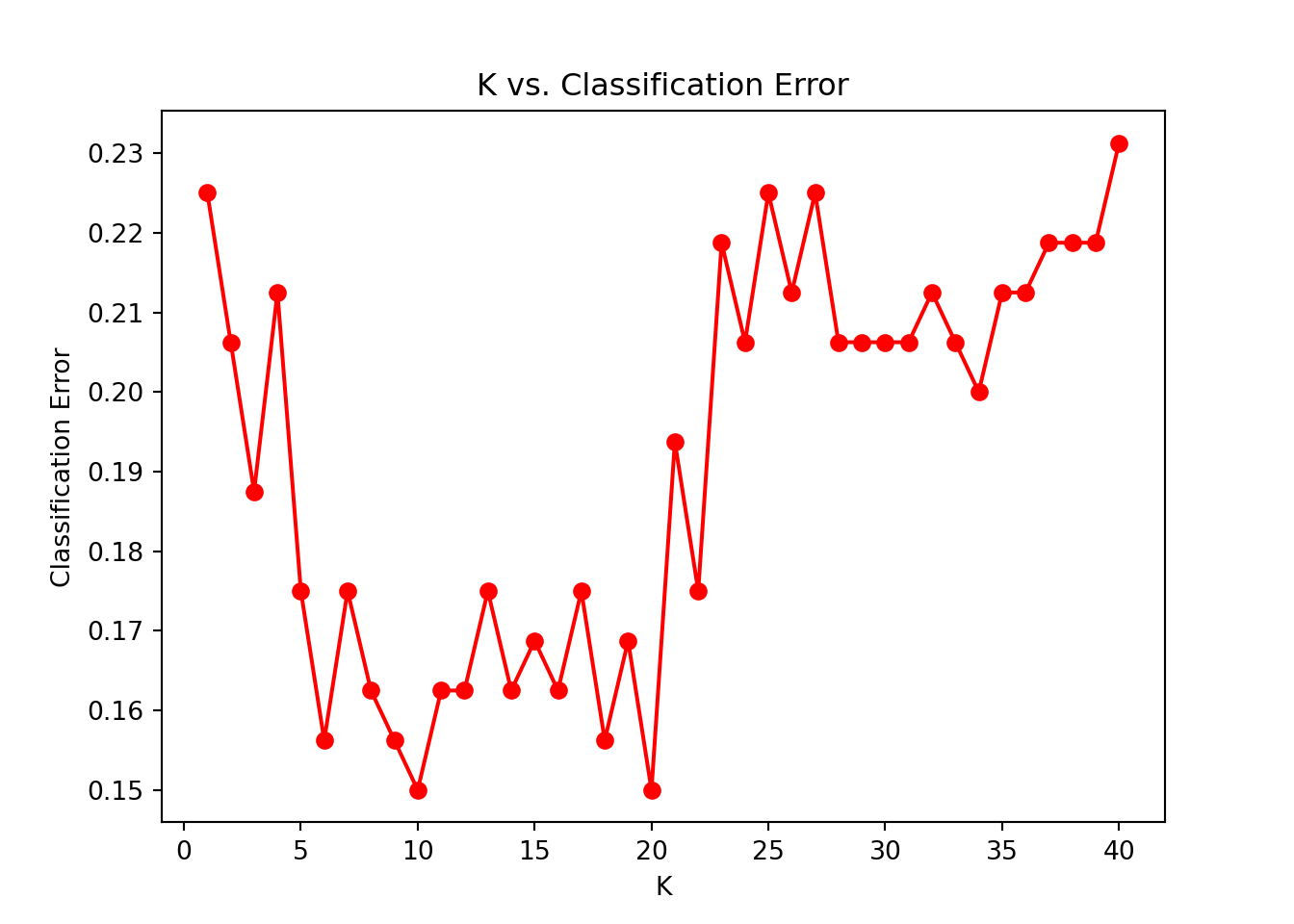
# Prepare train/test splitX_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=2025)# Perform 10-fold cross-validation for different k valuesk_values =range(1, 41)cv_errors = []for k in k_values: knn = KNeighborsClassifier(n_neighbors=k)# Use negative accuracy for error rate scores = cross_val_score(knn, X_train, y_train, cv=10, scoring='accuracy') cv_errors.append(1- np.mean(scores)) # Classification error = 1 - accuracy# Plot classification error vs. kplt.figure()plt.plot(k_values, cv_errors, marker='o', linestyle='-', color='red')plt.xlabel('K')plt.ylabel('Classification Error')plt.title('K vs. Classification Error')plt.show()
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
pd.DataFrame(confusion_matrix(y_test, knn_pred), index=[f"Actual {int(i)}"for i in np.unique(y_test)], columns=[f"Pred {int(i)}"for i in np.unique(y_test)])
Pred 0 Pred 1 Pred 2 Pred 3 ... Pred 6 Pred 7 Pred 8 Pred 9
Actual 0 355 0 3 0 ... 0 0 0 1
Actual 1 0 258 0 0 ... 2 1 0 0
Actual 2 8 0 183 1 ... 0 2 3 0
Actual 3 3 0 2 153 ... 0 1 0 1
Actual 4 0 2 0 0 ... 2 2 1 8
Actual 5 5 0 3 3 ... 0 0 1 4
Actual 6 3 1 1 0 ... 163 0 0 0
Actual 7 0 1 1 1 ... 0 138 1 1
Actual 8 4 0 3 4 ... 0 1 151 2
Actual 9 2 0 0 0 ... 0 4 0 168
[10 rows x 10 columns]
Source Code
---title: "11 - K Nearest Neighbors Code Demo"author: 'Dr. Cheng-Han Yu'format: html: toc: true code-link: true code-fold: show # code-summary: "Show/Hide" code-tools: true number-sections: true# filters: # - include-code-files---## R implementation```{r}load("../data/ESL.mixture.rda", verbose =TRUE)x <- ESL.mixture$xy <- ESL.mixture$ylibrary(class)library(caret)knn_fit <- class::knn(train = x, test = x, cl = y, k =15)caret::confusionMatrix(table(knn_fit, y))``````{r}set.seed(2025)control <-trainControl(method ="cv", number =10)knn_cvfit <-train(y ~ ., method ="knn", data =data.frame("x"= x, "y"=as.factor(y)),tuneGrid =data.frame(k =seq(1, 40, 1)),trControl = control)par(mar =c(4, 4, 0, 0))plot(knn_cvfit$results$k, 1- knn_cvfit$results$Accuracy,xlab ="K", ylab ="Classification Error", type ="b",pch =19, col =2)``````{r}zip.train <-read.csv("../data/zip.train.csv")zip.test <-read.csv("../data/zip.test.csv")# fit 3nn model and calculate the errorknn.fit <- class::knn(zip.train[, 2:257], zip.test[, 2:257], zip.train[, 1], k =3)# overall prediction errormean(knn.fit != zip.test[, 1])# the confusion matrixtable(knn.fit, zip.test[, 1], dnn =c("pred", "true"))```## Python implementation```{python}import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import cross_val_scorefrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import confusion_matriximport rdata``````{python}# Load the .rda file into a dictionarymixture_example = rdata.read_rda('../data/ESL.mixture.rda')x = mixture_example['ESL.mixture']['x']y = mixture_example['ESL.mixture']['y']``````{python}knn = KNeighborsClassifier(n_neighbors=15)knn.fit(x, y)pred = knn.predict(x)pd.DataFrame(confusion_matrix(y, pred), index=[f"Actual {int(i)}"for i in np.unique(y)], columns=[f"Pred {int(i)}"for i in np.unique(y)])``````{python}# Prepare train/test splitX_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=2025)# Perform 10-fold cross-validation for different k valuesk_values =range(1, 41)cv_errors = []for k in k_values: knn = KNeighborsClassifier(n_neighbors=k)# Use negative accuracy for error rate scores = cross_val_score(knn, X_train, y_train, cv=10, scoring='accuracy') cv_errors.append(1- np.mean(scores)) # Classification error = 1 - accuracy# Plot classification error vs. kplt.figure()plt.plot(k_values, cv_errors, marker='o', linestyle='-', color='red')plt.xlabel('K')plt.ylabel('Classification Error')plt.title('K vs. Classification Error')plt.show()``````{python}zip_train = pd.read_csv("../data/zip.train.csv",).to_numpy()zip_test = pd.read_csv("../data/zip.test.csv",).to_numpy()x_train = zip_train[:, 1:257]y_train = zip_train[:, 0]x_test = zip_test[:, 1:257]y_test = zip_test[:, 0]knn = KNeighborsClassifier(n_neighbors=3)knn.fit(x_train, y_train)knn_pred = knn.predict(x_test)np.mean(knn_pred != y_test)pd.DataFrame(confusion_matrix(y_test, knn_pred), index=[f"Actual {int(i)}"for i in np.unique(y_test)], columns=[f"Pred {int(i)}"for i in np.unique(y_test)])```