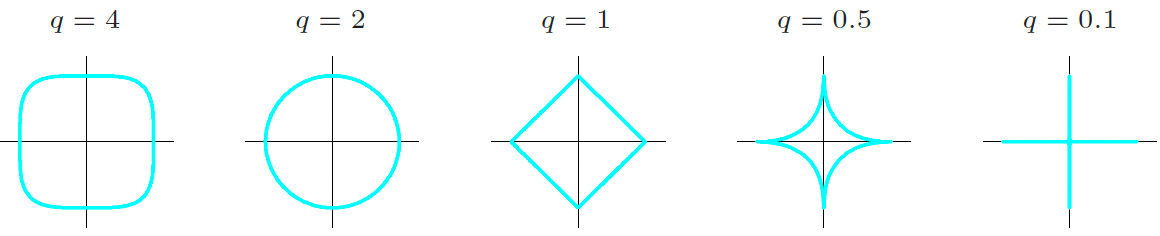Dr. Cheng-Han Yu Department of Mathematical and Statistical Sciences Marquette University
Feature/Variable Selection
When OLS Doesn’t Work Well
When \(p \gg n\), it is often that many of the features in the model are not associated with the response.
Model Interpretability: By removing irrelevant features \(X_j\)s, i.e., setting the corresponding \(\beta_j\)s to zero, we can obtain a model that is more easily interpreted. (Feature/Variable selection)
Least squares is unlikely to yield any coefficient estimates that are exactly zero.
Variable Selection
We have a large pool of candidate regressors, of which only a few are likely to be important.
Two “conflicting” goals in model building:
as many features as possible for better predictive performance on new data (smaller bias).
as few regressors as possible because as the number of regressors increases,
\(\mathrm{Var}(\hat{y})\) will increase (larger variance)
cost more in data collecting and maintaining
more model complexity
A compromise between the two hopefully leads to the “best” regression equation.
What does best mean?
There is no unique definition of “best”, and different methods specify different subsets of the candidate regressors as best.
Three Classes of Methods
Subset Selection (ISL Sec. 6.1) Identify a subset of the \(p\) predictors that we believe to be related to the response.
Need a selection method and a selection criterion.
Shrinkage (ISL Sec. 6.2) Fit a model that forces some coefficients to be shrunk to zero.
Lasso (Discussed in MSSC 6250)
Dimension Reduction (ISL Sec. 6.3) Find \(m\) representative features that are linear combinations of the \(p\) original predictors (\(m \ll p\)), then fit least squares.
Principal component regression (Unsupervised)
Partial least squares (Supervised)
Lasso (Least Absolute Shrinkage and Selection Operator)
Why Lasso?
Subset selection methods
may be computationally infeasible (fit OLS over millions of times)
do not explore all possible subset models (no global solution)
Ridge regression does shrink coefficients, but still include all predictors.
Lasso regularizes coefficients so that some coefficients are shrunk to zero, doing feature selection.
Like ridge regression, for a given \(\lambda\), Lasso only fits a single model.
What is Lasso?
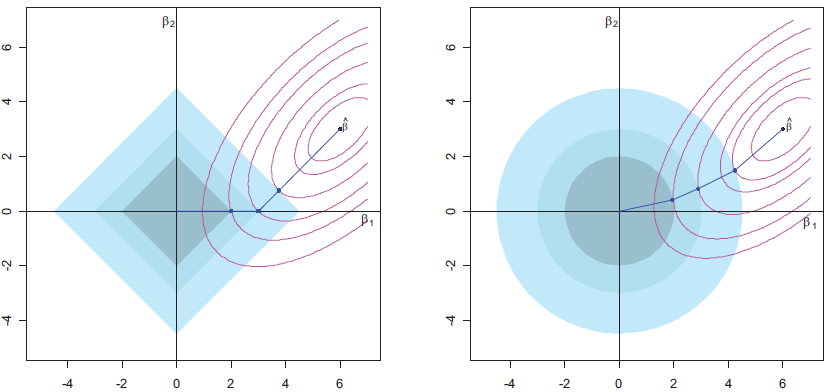
Different from the Ridge regression that adds \(\ell_2\) norm, Lasso adds \(\ell_1\) penalty on the parameters:
The \(\ell_1\) penalty forces some of the coefficient estimates to be exactly equal to zero when \(\lambda\) is sufficiently large, yielding sparse models.
\(\ell_2\) vs. \(\ell_1\)
Ridge shrinks big coefficients much more than lasso.
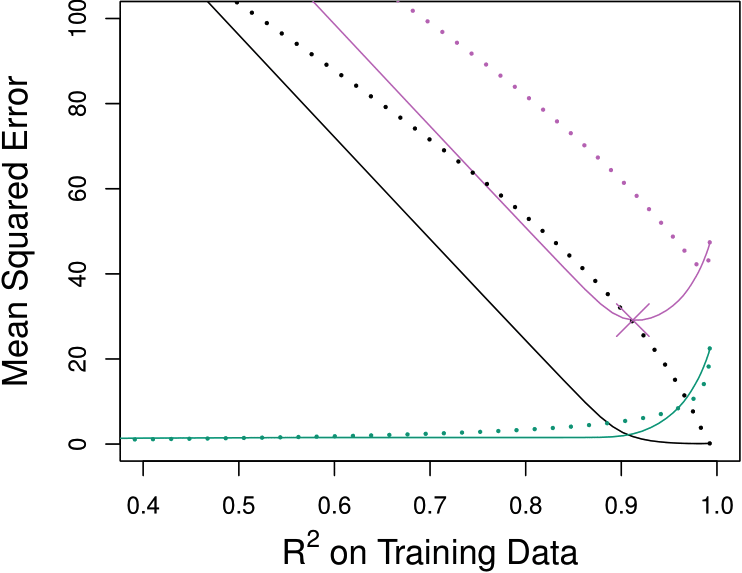
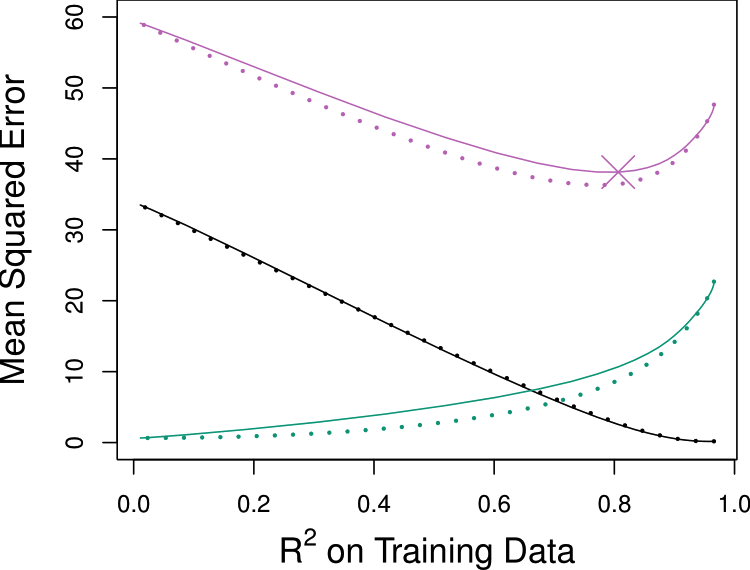
A relatively small number of \(\beta_j\)s are substantially large, and the remaining \(\beta_k\)s are small or equal to zero.
Reduce more bias
ISL Fig. 6.9
Ridge (\(\cdots\cdots\))
The response is a function of many predictors, all with coefficients of roughly equal size.
Reduce more variance
ISL Fig. 6.8
Bayesian Interpretation
Lasso
Ridge
Let’s wait until we discuss Bayesian Regression!
Notes of Lasso
Warning
Even Lasso does feature selection, do NOT add predictors that are known to be not associated with the response in any way.
Curse of dimensionality. The test MSE tends to increase as the dimensionality \(p\) increases, unless the additional features are truly associated with the response.
Do NOT conclude that the predictors with non-zero coefficients selected by Lasso and other selection methods predict the response more effectively than other predictors not included in the model.